Client
A United Kingdom-based AI research organization working on advanced computer vision models that require highly accurate human semantic segmentation data.
The Challenge
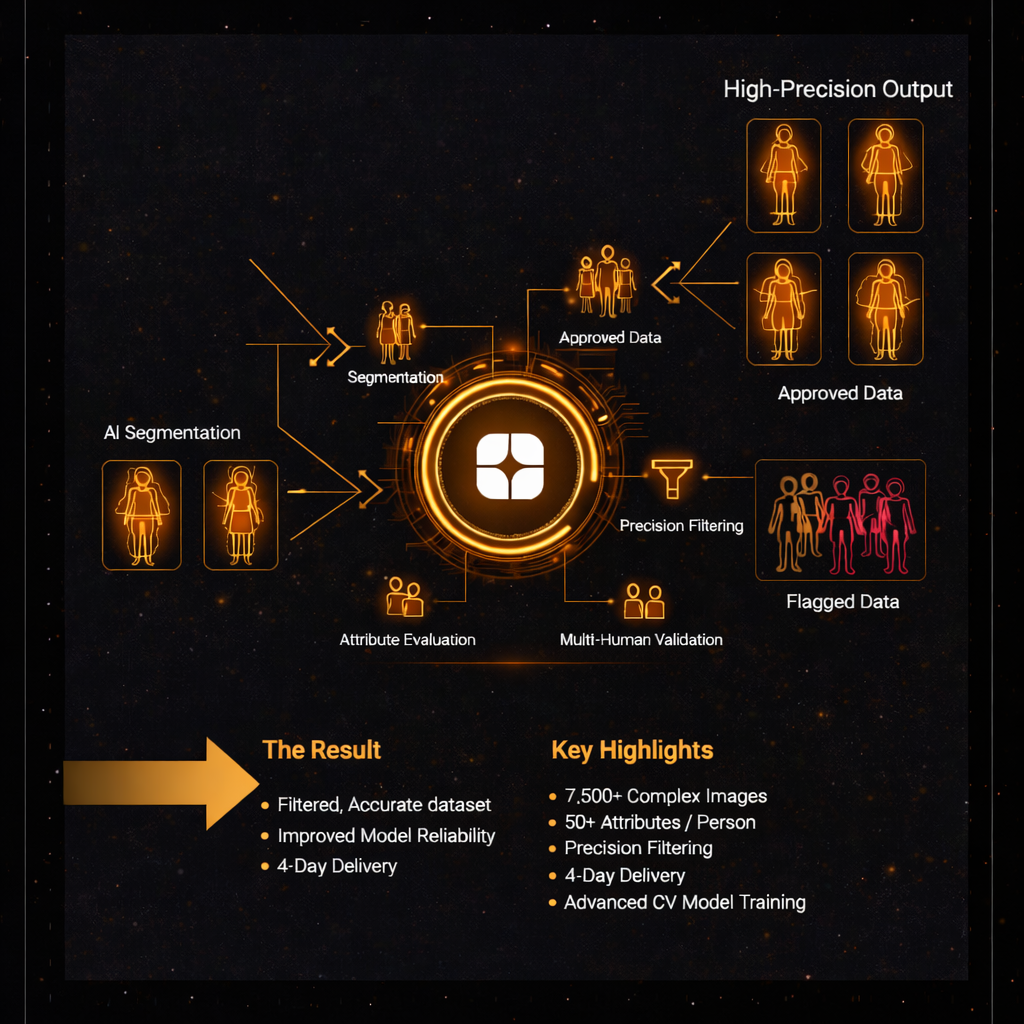
Human semantic segmentation becomes significantly more complex when multiple people appear in a single image. In this project, every image contained several individuals, each annotated with 50+ human attributes, all generated through AI-based semantic segmentation.
While automation enabled scale, the client faced a critical issue. The annotations lacked the precision required for high-grade model training. Errors included incorrect attribute tagging, boundary inaccuracies, and inconsistencies across overlapping human regions.
The client needed a rapid yet rigorous review to:
- Evaluate whether each attribute was correctly tagged
- Verify segmentation precision for multiple humans in the same image
- Retain only high-quality annotations suitable for model training
- Flag and isolate incorrectly annotated data
The scope involved 7,500+ highly complex images, all to be reviewed and filtered within four working days.
The Solution
Globik AI deployed a focused human-in-the-loop review pipeline designed for dense semantic segmentation scenarios.
- Attribute-Level Evaluation
Each image was reviewed at the attribute level to verify correct tagging across more than 50 human attributes per subject.
- Multi-Human Segmentation Validation
Reviewers assessed segmentation boundaries where multiple humans overlapped, ensuring accuracy in separation and labeling.
- Precision-Based Filtering
Images that met the required annotation standards were approved and retained, while those with inaccuracies were flagged for exclusion or rework.
- High-Speed Review Workflow
Parallel review pipelines and quality checkpoints enabled the team to process the full dataset within the tight delivery window.
The Result
Within working days, Globik AI delivered a clean, filtered, and high-precision dataset ready for advanced model training.
The client achieved:
- A trusted subset of accurately annotated images
- Elimination of noisy and misleading training data
- Improved reliability of downstream semantic segmentation models
- Faster experimentation cycles without annotation-related rework
Real-World Use Cases
- Human-Centric Computer Vision Models
Training models that require precise understanding of multiple humans in a single scene.
- AR and VR Applications
Enabling accurate human segmentation for immersive digital experiences.
- Robotics and Automation
Supporting perception systems that rely on correct human detection and attribute recognition.
- Advanced Research Models
Strengthening foundational vision models by removing low-quality training inputs.
Why It Matters
Semantic segmentation models do not fail because of scale. They fail because of subtle inaccuracies that compound during training.
By introducing expert-led review and precision-based filtering, Globik AI ensured that only the most reliable annotations entered the client’s training pipeline. This reduced noise at the data layer and improved overall model performance.
This case demonstrates Globik AI’s ability to handle high-density, attribute-rich visual datasets with speed, accuracy, and consistency.
Key Highlights
- 7,500+ complex human images reviewed
- 50+ attributes evaluated per image
- Multi-human semantic segmentation validation
- Precision-based data filtering and flagging
- Delivered within four working days
- Designed for advanced computer vision model training