Client
An AI-driven organization building speech and language models that require high-quality, regionally accurate Indian language datasets at scale.
The Challenge
Indian language speech data is inherently complex. Variations in accent, pronunciation, pacing, and contextual usage often break generic transcription pipelines.
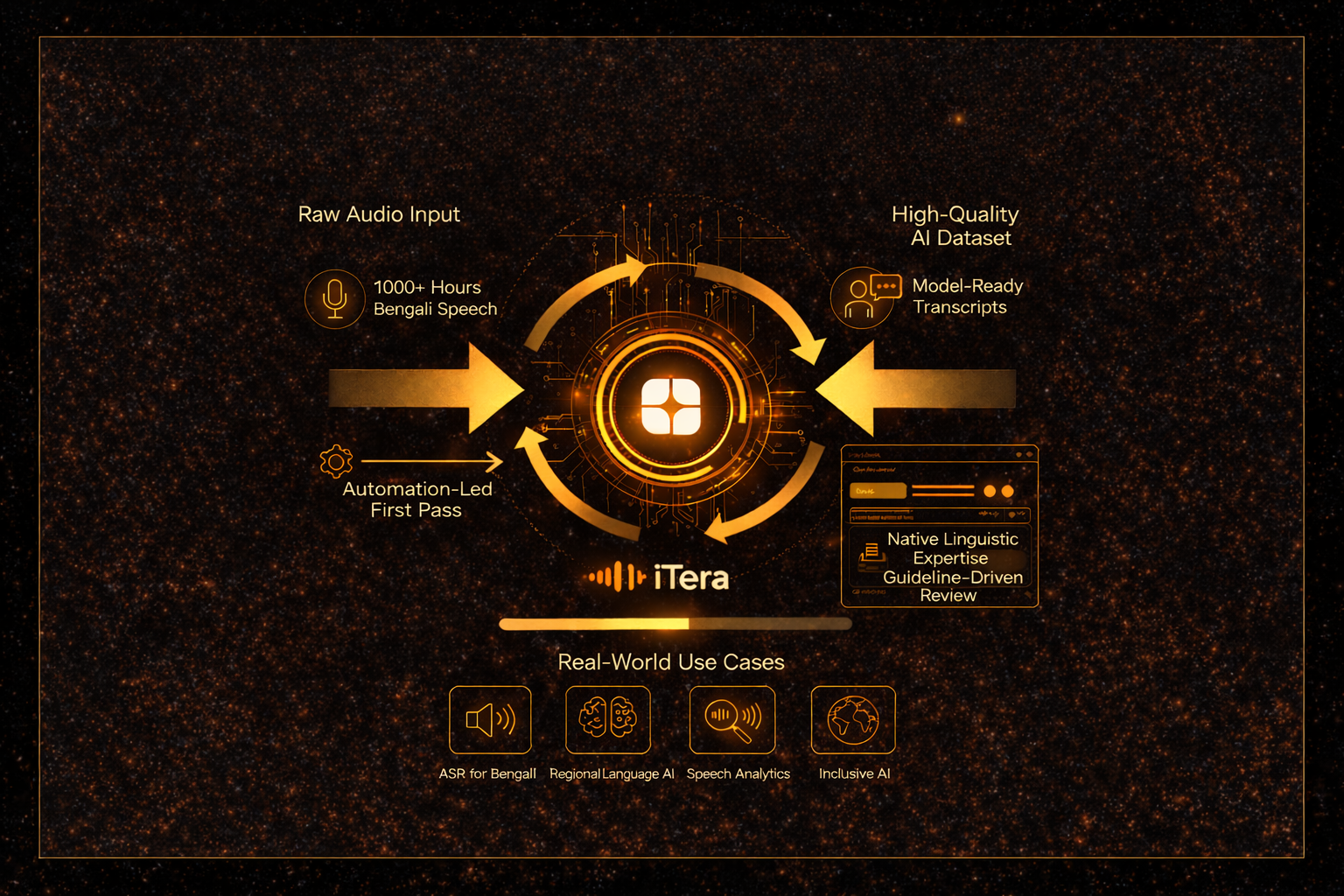
The client required 1,000 hours of Bengali audio to be transcribed and reviewed strictly according to predefined model-training guidelines. The dataset included real-world speech patterns, background noise, speaker variability, and contextual linguistic nuances that could not be handled through automation alone.
The key challenges were:
- Sourcing and managing native Bengali language experts at scale
- Maintaining consistency across thousands of hours of audio
- Ensuring transcription accuracy suitable for AI model training, not just human readability
- Delivering within a fixed timeline of 2 months without compromising quality
The client had struggled operationally to find a partner capable of handling both the scale and linguistic complexity of the project.
The Solution
Globik AI implemented a human-in-the-loop transcription pipeline using its proprietary platform, iTerra, combining automation with expert linguistic validation.
- Automation-Led First Pass
An initial automated transcription layer accelerated processing and ensured uniform baseline outputs across the dataset.
- Native Linguistic Expertise
The automated outputs were then reviewed, corrected, and contextually refined by native Bengali language experts, ensuring accurate interpretation of idioms, colloquial expressions, and region-specific speech patterns.
- Guideline-Driven Review Process
All transcription and review workflows were aligned with the client’s AI training guidelines, ensuring consistency, normalization, and model-ready outputs.
- Scalable Quality Control
Multi-level reviews and sampling audits were built into the pipeline to maintain quality across the entire 1,000-hour dataset.
The Result
Globik AI successfully delivered 1,000 hours of high-quality Bengali transcriptions within two months, meeting both accuracy and timeline expectations.
Key outcomes included:
- Model-ready transcriptions with high linguistic fidelity
- Consistent annotation quality across large volumes of speech data
- Reduced turnaround time through automation-assisted workflows
- A reliable dataset suitable for speech recognition and language model training
The client was able to proceed confidently with downstream model development without rework or data quality concerns.
Real-World Use Cases
- Automatic Speech Recognition (ASR) for Bengali
Training robust ASR models capable of handling native accents and real-world speech variability.
- Regional Language AI Systems
Powering voice assistants, IVR systems, and conversational AI in Bengali.
- Speech Analytics and Intelligence
Enabling accurate sentiment, intent, and content analysis in regional language conversations.
- Inclusive AI Development
Expanding AI accessibility for non-English and underrepresented language speakers.
Why It Matters
High-quality speech AI does not start with models. It starts with linguistically accurate, context-aware data. By combining automation with native language expertise, Globik AI ensured that every transcription captured not just words, but meaning, intent, and cultural nuance.
This project demonstrates Globik AI’s ability to deliver large-scale, high-complexity language datasets efficiently, without compromising on accuracy or linguistic integrity.
Key Highlights
- 1,000 hours of Bengali audio transcribed and reviewed
- Two-month delivery timeline
- Native Bengali language experts onboarded at scale
- Human-in-the-loop workflow via iTera platform
- Automation-assisted first-layer transcription
- Model-training–ready outputs
- Designed for speech and language AI systems