Artificial Intelligence is evolving rapidly, but the rules governing how it is built and deployed are evolving just as fast. One of the most significant regulatory developments shaping the AI ecosystem today is the EU AI Act. For organizations developing or deploying AI systems, especially those that rely on large amounts of training data, this regulation introduces new responsibilities.
At the center of these responsibilities lies a critical element that often goes unnoticed outside technical teams. That element is data annotation.
AI models learn from the data they are trained on. If the data is biased, incomplete, or poorly labeled, the model will reflect those weaknesses. Regulators in the European Union recognize this reality. The EU AI Act places strong emphasis on the quality, traceability, and governance of training datasets used in AI systems.
In this blog, we explore what the EU AI Act means for AI development, how data annotation plays a central role in compliance, and how enterprises can prepare for the future of regulated AI.
The EU AI Act is the world’s first comprehensive legal framework designed specifically for artificial intelligence systems. Its purpose is simple. Ensure that AI systems are safe, transparent, and trustworthy when used in real-world environments.
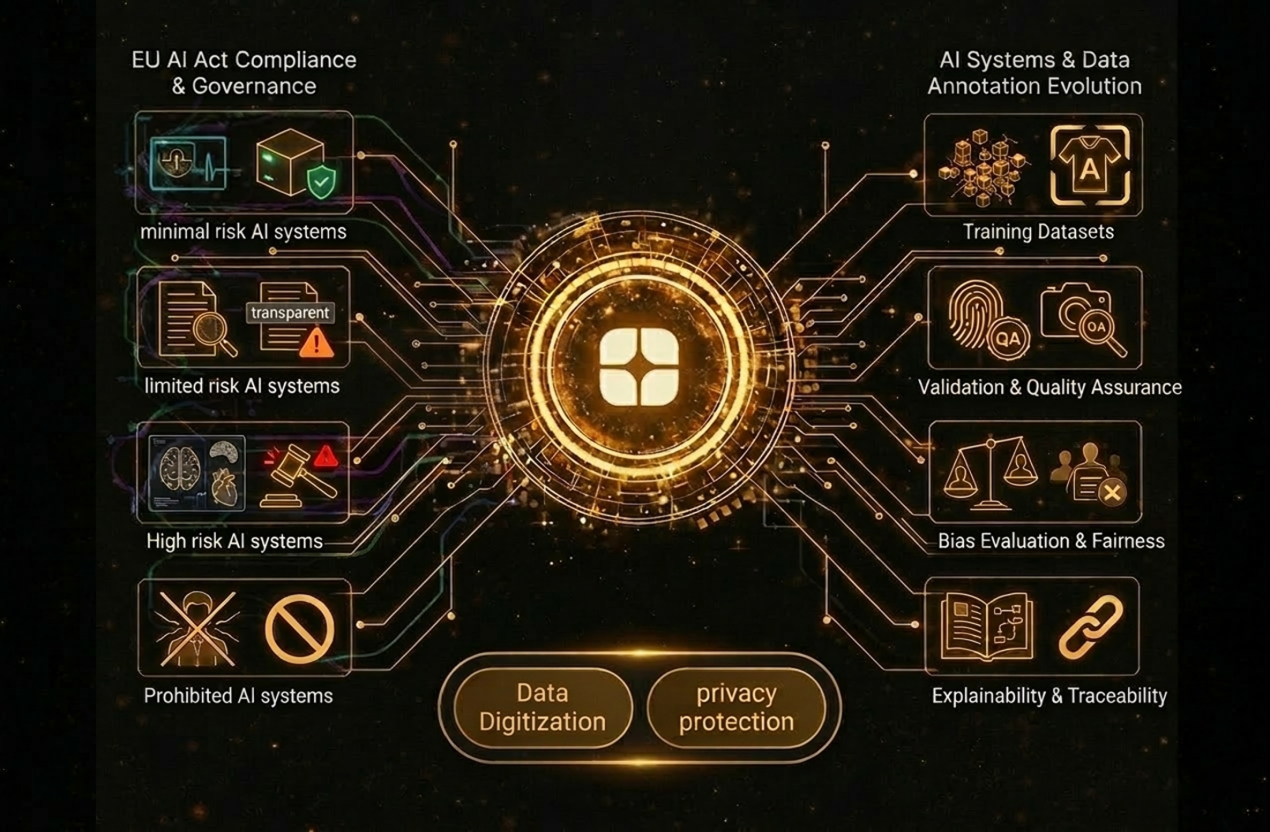
Rather than regulating AI broadly, the Act categorizes systems based on their level of risk. These categories include:
High risk systems receive the most regulatory scrutiny. These include AI used in healthcare diagnostics, financial credit scoring, recruitment decisions, law enforcement applications, and critical infrastructure monitoring.
For these systems, the regulation requires strict documentation, testing, transparency, and dataset governance. This is where data annotation becomes extremely important. AI models trained on poorly documented or poorly structured datasets may fail compliance audits. Enterprises must prove that their data pipelines follow responsible practices and that datasets used for training models are accurate, unbiased, and traceable.
Data annotation is the process of labeling raw data so that AI models can understand patterns and relationships. Images are tagged with objects, text is categorized by meaning, and audio is labeled by speaker or intent. While this process may seem technical, regulators now consider it a core element of AI accountability.
The EU AI Act emphasizes several data requirements for AI systems:
Without structured annotation workflows, meeting these requirements becomes extremely difficult. Companies that rely on generic or outsourced labeling processes without proper governance risk building models that fail regulatory checks. This shift is why enterprises are increasingly turning to specialized AI data providers who combine annotation expertise with compliance readiness.
Globik AI, for example, focuses on delivering structured datasets and responsible AI pipelines that support real world deployment across regulated industries. Globik AI
Data annotation today is no longer a simple labeling exercise. It is part of a broader responsible AI workflow that includes:
Organizations building AI must treat these steps as a single pipeline rather than isolated tasks.
According to Globik AI’s enterprise data services approach, high quality datasets require structured workflows, subject matter expertise, and continuous validation to ensure that AI models behave reliably in real world conditions. This integrated approach is becoming essential for compliance with the EU AI Act.
To comply with the EU AI Act, organizations must rethink how they prepare and manage training datasets. Below are the most important aspects enterprises should focus on.
AI models must be trained on datasets that reflect the environments where they will operate.
For example, a healthcare diagnostic model trained only on data from one region or demographic group may produce inaccurate outcomes for others. Regulators expect organizations to demonstrate that datasets cover diverse scenarios.
Annotation teams therefore need to follow clear labeling guidelines and ensure balanced representation across categories.
The EU AI Act requires enterprises to document how AI systems are trained.
This means organizations must be able to answer questions such as:
Platforms that maintain audit trails, version history, and annotation guidelines help enterprises maintain this level of transparency. Modern AI data platforms also integrate annotation workflows with automated quality monitoring so datasets remain consistent throughout the project lifecycle.
Bias is one of the biggest concerns in AI regulation. If training data contains hidden bias, AI systems can produce unfair outcomes.
Annotation workflows must therefore include:
Human oversight remains essential. Even the most advanced automated systems still rely on human judgment to identify nuanced bias patterns in datasets.
Many AI systems rely on sensitive data such as medical records, financial transactions, or personal communications. The EU AI Act works closely with existing privacy frameworks such as the General Data Protection Regulation. As a result, organizations must ensure that personal information used in datasets is anonymized or de-identified. Data digitization and privacy protection services help transform raw records into structured datasets while maintaining regulatory compliance.
The EU AI Act will affect almost every industry that uses AI. Below are examples of how annotation and compliance intersect across different sectors.
Healthcare AI systems are often classified as high risk because they influence clinical decisions. AI models used for medical imaging, diagnostics, or patient triage must be trained on highly accurate datasets. Annotation teams often include clinicians who can label radiology scans, pathology slides, and clinical text with medical precision. Healthcare datasets also require strict anonymization to protect patient privacy.
For example, annotated medical imaging datasets help AI models detect diseases from X rays and MRI scans while maintaining patient confidentiality.
Financial institutions rely heavily on AI for fraud detection, credit scoring, and risk assessment. These systems must demonstrate fairness and transparency. If an AI model rejects a loan application, organizations must explain the reasoning behind that decision. Structured datasets that label financial transactions, risk signals, and regulatory information help ensure that models behave predictably and transparently. Annotation quality directly influences the reliability of these systems.
Insurance companies use AI to evaluate claims, detect fraud, and assess risk. Image annotation of vehicle damage, property inspections, and accident scenes allows AI systems to analyze claims quickly. However, datasets must be carefully curated to prevent bias and ensure fair outcomes. Under the EU AI Act, insurers must also document how their models are trained and evaluated.
Autonomous vehicles depend on enormous volumes of annotated sensor data. Cameras, radar, and LiDAR sensors capture road environments. Annotation teams then label objects such as vehicles, pedestrians, traffic signals, and road boundaries. To meet regulatory expectations, datasets must include diverse weather conditions, traffic patterns, and geographical environments. Synthetic data simulation is often used to generate rare driving scenarios that are difficult to capture in the real world.
Retail AI focuses on recommendation systems, search relevance, and customer experience. Annotated product catalogs, customer reviews, and behavioral datasets allow AI models to deliver personalized shopping experiences. While these systems typically fall under lower risk categories, companies must still ensure that datasets respect privacy rules and avoid discriminatory outcomes.
Industrial AI systems monitor production lines, detect defects, and predict equipment failures. Annotation of industrial imagery and sensor data enables AI models to recognize faults in machinery or product quality issues. These datasets must be consistent and well documented to ensure reliable model performance.
For companies operating in the European market, maintaining detailed records of data preparation processes will become increasingly important.
Consider a financial institution developing an AI model to detect fraudulent transactions.
Initially, the organization relied on internal data scientists to label a limited set of transaction records. The model performed well during testing but struggled with new fraud patterns once deployed.
To address this, the company introduced a structured annotation pipeline with subject matter experts reviewing suspicious transaction patterns. The dataset was expanded to include diverse fraud scenarios and historical cases.
After retraining the model with the improved dataset, detection accuracy improved significantly and false positive rates declined.
More importantly, the organization now had documented annotation workflows and dataset governance processes that could support regulatory audits.
Enterprises increasingly rely on specialized platforms to manage large scale annotation workflows. These platforms integrate automation, human validation, and governance tools to ensure data quality and traceability.
Globik AI, for example, provides an enterprise annotation environment designed for complex AI projects. Its platform supports multiple data types such as images, audio, video, and text while maintaining structured workflows and audit trails.
Human in the loop review systems also help organizations combine machine speed with human expertise, improving both accuracy and accountability.
The EU AI Act represents the beginning of a broader shift toward regulated artificial intelligence. Other regions including the United States, the United Kingdom, and parts of Asia are exploring similar frameworks. Enterprises that prepare early will have a significant advantage.
In the coming years, we are likely to see:
At the center of these changes will remain one fundamental principle. AI systems must be built on trustworthy data.
Organizations that want to stay ahead of regulatory requirements should consider several steps.
First, audit existing datasets and annotation pipelines to identify potential gaps in documentation or quality control.
Second, establish clear annotation guidelines and quality assurance processes.
Third, work with AI data partners that understand both technology and compliance requirements.
Companies that adopt structured data strategies today will find it easier to adapt as global AI regulations continue to evolve.
The EU AI Act is reshaping how artificial intelligence systems are built, evaluated, and deployed. While much of the conversation focuses on algorithms and model performance, the reality is simpler. Responsible AI begins with responsible data. Data annotation is not just a technical step in the AI pipeline. It is the foundation that determines whether a model is accurate, fair, and compliant with regulatory expectations.
Enterprises that treat annotation as a strategic capability rather than a background task will be better positioned to succeed in a regulated AI future.
Organizations like Globik AI are helping enterprises navigate this transformation by delivering structured datasets, responsible AI frameworks, and scalable annotation workflows that meet the demands of modern AI systems.
As regulation and innovation continue to evolve together, one thing is clear. The future of AI will belong to companies that build intelligence on a strong and trustworthy data foundation.